目录
- 对象底层
- alloc的调用流程
- init方法
- 编译器优化
- 内存(对象、结构体)对齐方式
- 影响对象的内存因素
- 联合体、位域
- new方法
- objc_object的isa结构
- nonPointerIsa的概念
- 利用isa进行位运算
- isa指向分析
- 类、元类继承关系
- objc_class的bits
- isa的bits,获取方法列表、协议列表
- ivar的存储位置
- ro、rw、rwe
- runtime的API分析方法列表、成员变量、协议列表
- objc_class的cache(方法的缓存)
- 缓存方法
- 添加方法的缓存:void insert(SEL sel, IMP imp, id receiver);
- 获取缓存的方法:buckets()得到bucket_t;
- 缓存方法的实现地址:bucket_t.imp(nil, 类对象)
- 缓存方法的实现地址:bucket_t.sel(),
- cache扩容
- cache_t解析
- cache扩容规则
- 缓存方法
- 消息机制
- objc_msgSendSuper分析
- 方法的快速查找
- 方法的慢速查找
- 方法的动态决议
- 方法的快速转发
- 方法的慢速转发
- 符号断点
- _objc_init
- libdispatch_init
- libSystem_initializer
- objc_alloc
- callAlloc
- objc_msgSend
- alloc
概要
alloc⽅法的底层调⽤流程
- alloc —> objc_alloc —> callAlloc —> objc_msgSend —>
- alloc —> _objc_rootAlloc —> callAlloc —> _objc_rootAllocWithZone —> _class_createInstanceFromZone
说明:alloc走两次与fixupMessageRef相关
alloc核心实现在_class_createInstanceFromZone,如下 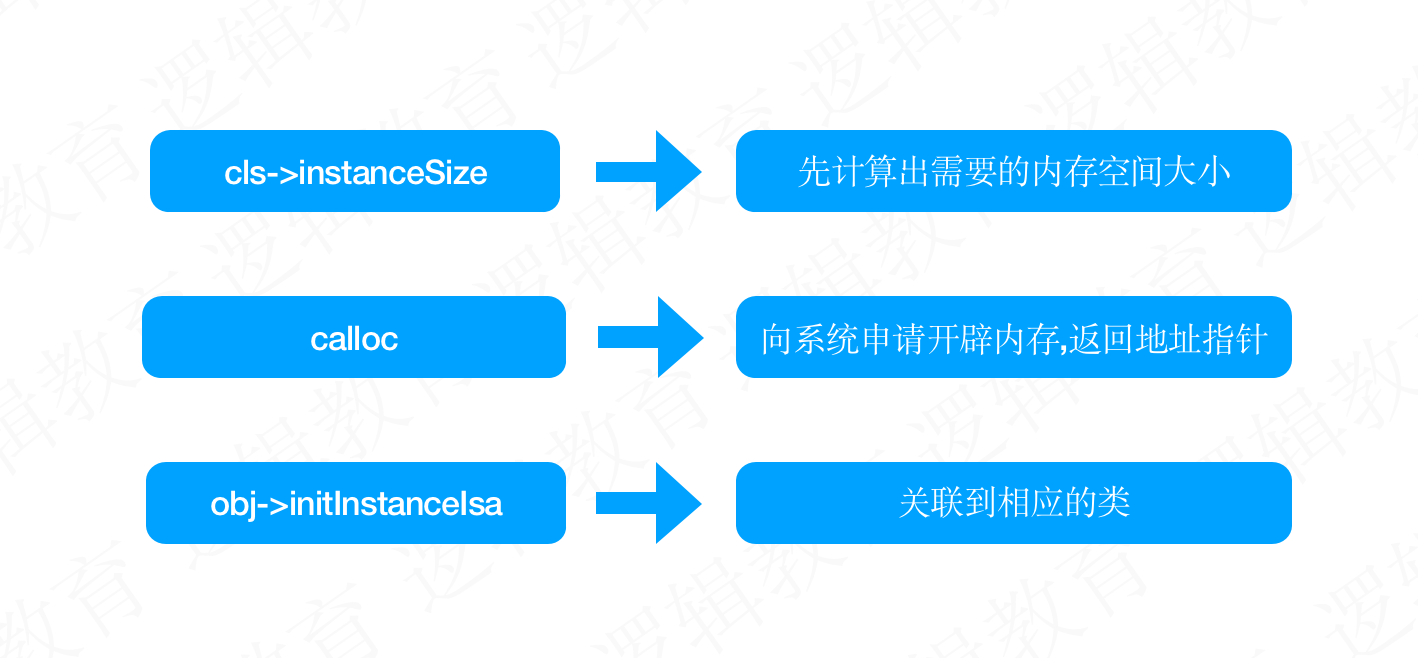
为什么要字节对⻬?
字节是内存的容量单位。但是,CPU在读取内存的时候,却不是以字节为单位来读取的,⽽是以 “块”为单位读取的,所以⼤家也经常听到⼀块内存,“块”的⼤⼩也就是内存存取的⼒度。如果不 对⻬的话,在我们频繁的存取内存的时候,CPU就需要花费⼤量的精⼒去分辨你要读取多少字节, 这就会造成CPU的效率低下,如果想要CPU能够⾼效读取数据,那就需要找⼀个规范,这个规范就 是字节对⻬。
为什么对象内部的成员变量是以8字节对⻬,系统实际分配的内存以16字节对⻬?
以空间换时间。苹果采取16字节对⻬,是因为OC的对象中,第⼀位叫isa指针,它是必然存在的, ⽽且它就占了8位字节,就算对象中没有其他的属性了,也⼀定有⼀个isa,那对象就⾄少要占⽤8 位字节。如果以8位字节对⻬的话,如果连续的两块内存都是没有属性的对象,那么它们的内存空 间就会完全的挨在⼀起,是容易混乱的。以16字节为⼀块,这就保证了CPU在读取的时候,按照块 读取就可以,效率更⾼,同时还不容易混乱。
对象的本质
objc_object结构体,⾥⾯存储isa指针和成员变量的值。
计算机存储单位
- bit:二进制位,简称b。是计算机中数据的最小单位。
- Byte:字节,简称B。字节称为电脑中表示信息含义的最小单位
- Word:字,两个字节称为一个字。汉字的存储单位都是一个字。
换算如下
- 8bit = 1Bytes
- 1024Bytes = 1KB
- 1024KB = 1MB
- 1024MB = 1GB
- 1024GB = 1TB
结构体的内存对⻬⽅式
- 1:数据成员对⻬规则:结构(struct)的第⼀个数据成员放在offset为0的地⽅,以后每个数据成员存 储的起始位置要从该成员⼤⼩或者成员的⼦成员⼤⼩的整数倍开始(⽐如int为4字节,则要从4的整 数倍地址开始存储)。
- 2:结构体作为成员:如果⼀个结构⾥有某些结构体成员,则结构体成员要从其内部最⼤元素⼤⼩的整 数倍地址开始存储.(struct a⾥存有struct b,b⾥有char,int ,double等元素,那b应该从8的整数倍开始 存储)。
- 3:收尾⼯作:结构体的总⼤⼩,也就是sizeof的结果必须是其内部最⼤成员的整数倍,不⾜的要补⻬。
对齐算法
1
2
3
4
int WORD_MASK 7UL;
int word_align(int x) {
return (x + WORD_MASK) & ~WORD_MASK;
}
影响对象内存的因素
对象⾥⾯存储了⼀个isa指针 + 成员变量的值,isa指针是固定的,占8个字节,所以影响对象内存 的只有成员变量(属性会⾃动⽣成带下划线的成员变量)
对象的内存分布
在对象的内部是以8字节进⾏对⻬的。 苹果会⾃动重成员变量的顺序,将占⽤不⾜ 8 字节的成员挨在⼀起,凑满 8 字节,以达到优化内 存的⽬的。
联合体(union)
联合体⼜叫共⽤体,union就是在内存中划了⼀个⾜够⽤的空间,⾄于你怎么玩~它不管~!联合体 的成员变量就相当于为这块内存空间开辟了⼏个访问途径,他们共享这⼀块内存。 联合体的⼤⼩计算奉⾏俩个规则 1.联合体⼤⼩必须能容纳联合体中最⼤的成员变量 2.通过1计算出的联合体⼤⼩必须是联合体中占内存⼤⼩最⼤的基本数据类型⼤⼩的整数倍
联合体和结构体的区别
结构体(struct)中所有变量是“共存”的,⽽联合体(union)中是各变量是“互斥”的,只能存在⼀个。 struct内存空间的分配是粗放的,不管⽤不⽤,全部分配。这样带来的⼀个坏处就是对于内存的消 耗要⼤⼀些。但是结构体⾥⾯的数据是完整的。 联合体⾥⾯的数据只能存在⼀个,但优点是内存使⽤更为精细灵活,也节省了内存空间。
位域
位域的宽度不能超过前⾯数据类型的最⼤⻓度,⽐如int占4个字节也就是32位,那后⾯的数字就不 能超过32。 ⼀个位域存储在同⼀个字节中,如⼀个字节所剩空间不够存放另⼀位域时,则会从下⼀单元起存放 该位域。 位域能够节省⼀定的内存空间。
结构体、联合体、位域区别
- 结构体struct中所有变量都是共存的,缺点是结构体内存空间的分配是粗放的,不管用不用都会分配。
- 联合体union中各变量是互斥的,优点是内存使用更精细灵活,节省了内存空间。一般联合体搭配位域一起使用。
- 位域:按位分配内存大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// 结构体
struct OCBike1 {
BOOL front;
BOOL back;
BOOL left;
BOOL right;
};
// 联合体
union OCBike1 {
BOOL front;
BOOL back;
BOOL left;
BOOL right;
};
// 位域
BOOL front: 1;
// 联合体 + 位域
union OCBike1 {
BOOL front: 1;
BOOL back : 1;
BOOL left :1 ;
BOOL right : 1;
};
nonPointerIsa
nonPointerIsa是内存优化的⼀种⼿段。isa是⼀个Class类型的结构体指针,占8个字节,主要是⽤ 来存内存地址的。但是8个字节意味着它就有8*8=64位。存储地址根本不需要这么多的内存空间。 ⽽且每个对象都有个isa指针,这样就浪费了内存。所以苹果就把和对象⼀些息息相关的东⻄,存 在了这块内存空间⾥⾯。这种isa指针就叫nonPointerIsa。 nonPointerIsa存储的内容有:
isa指针的数据结构
arm64 (模拟器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# if __arm64__
// ARM64 simulators have a larger address space, so use the ARM64e
// scheme even when simulators build for ARM64-not-e.
# if __has_feature(ptrauth_calls) || TARGET_OS_SIMULATOR
# define ISA_MASK 0x007ffffffffffff8ULL
# define ISA_MAGIC_MASK 0x0000000000000001ULL
# define ISA_MAGIC_VALUE 0x0000000000000001ULL
# define ISA_HAS_CXX_DTOR_BIT 0
# define ISA_BITFIELD \
uintptr_t nonpointer : 1; \
uintptr_t has_assoc : 1; \
uintptr_t weakly_referenced : 1; \
uintptr_t shiftcls_and_sig : 52; \
uintptr_t has_sidetable_rc : 1; \
uintptr_t extra_rc : 8
# define RC_ONE (1ULL<<56)
# define RC_HALF (1ULL<<7)
arm64 (真机)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# else
# define ISA_MASK 0x0000000ffffffff8ULL
# define ISA_MAGIC_MASK 0x000003f000000001ULL
# define ISA_MAGIC_VALUE 0x000001a000000001ULL
# define ISA_HAS_CXX_DTOR_BIT 1
# define ISA_BITFIELD \
uintptr_t nonpointer : 1; \
uintptr_t has_assoc : 1; \
uintptr_t has_cxx_dtor : 1; \
uintptr_t shiftcls : 33; /*MACH_VM_MAX_ADDRESS 0x1000000000*/ \
uintptr_t magic : 6; \
uintptr_t weakly_referenced : 1; \
uintptr_t unused : 1; \
uintptr_t has_sidetable_rc : 1; \
uintptr_t extra_rc : 19
# define RC_ONE (1ULL<<45)
# define RC_HALF (1ULL<<18)
# endif
x86_64
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# elif __x86_64__
# define ISA_MASK 0x00007ffffffffff8ULL
# define ISA_MAGIC_MASK 0x001f800000000001ULL
# define ISA_MAGIC_VALUE 0x001d800000000001ULL
# define ISA_HAS_CXX_DTOR_BIT 1
# define ISA_BITFIELD \
uintptr_t nonpointer : 1; \
uintptr_t has_assoc : 1; \
uintptr_t has_cxx_dtor : 1; \
uintptr_t shiftcls : 44; /*MACH_VM_MAX_ADDRESS 0x7fffffe00000*/ \
uintptr_t magic : 6; \
uintptr_t weakly_referenced : 1; \
uintptr_t unused : 1; \
uintptr_t has_sidetable_rc : 1; \
uintptr_t extra_rc : 8
# define RC_ONE (1ULL<<56)
# define RC_HALF (1ULL<<7)
- nonpointer:表示是否对 isa 指针开启指针优化 0:纯isa指针,1:不止是类对象地址,isa 中包含了类信息、对象的引用计数等
- has_assoc:关联对象标志位,0没有,1存在
- has_cxx_dtor:该对象是否有 C++ 或者 Objc 的析构器,如果有析构函数,则需要做析构逻辑, 如果没有,则可以更快的释放对象
- shiftcls: 存储类指针的值。开启指针优化的情况下,在 arm64 架构中有 33 位用来存储类指针。
- magic:用于调试器判断当前对象是真的对象还是没有初始化的空间
- weakly_referenced:表示对象是否被指向或者曾经指向一个 ARC 的弱变量, 没有弱引用的对象可以更快释放。
- deallocating:标志对象是否正在释放内存
- has_sidetable_rc:当对象引用技术大于 10 时,则需要借用该变量存储进位
- extra_rc:当表示该对象的引用计数值,实际上是引用计数值减 1, 例如,如果对象的引用计数为 10,那么 extra_rc 为 9。如果引用计数大于 10, 则需要使用到下面的 has_sidetable_rc。
类对象
类也是对象,类对象有且只有⼀个。类对象本质为objc_class结构体。类对象⾥⾯存储了类的⽗ 类、属性、实例⽅法、协议、成员变量、⽅法缓存等等。
isa指向关系
实例对象的isa->类对象 类对象的isa->元类 元类的isa->根元类 根元类的isa->根元类⾃⼰
ISA指针、父类、元类、根元类
 @w=400
@w=400
元类的继承关系
⽗类的元类就是元类的⽗类。根元类的⽗类就是NSObject。NSObject是万类之祖。
entsize_list_tt
entsize_list_tt 是个模板,可以实例化出method_list_t、ivar_list_t、property_list_t三种类型。
1
2
Element:表示元素类型 List:表示容器类型 FlagMask:标记位
template <typename Element, typename List, uint32_t FlagMask, typename PointerModifier = PointerModifierNop>
端序(大小端)
端序(Endian)有两种规则,一种是大端序,一种是小端序。大端序是指将高位字节存放在低位地址,而小端序则是将低位字节存放在低位地址。 ⽐如,我们要存储⼀个0x12345678这个数据,我们在内存的0x1001开始存放。
| 内存地址 | ⼤端序 | ⼩端序 |
|---|---|---|
| 0x1001 | 0x12 | 0x78 |
| 0x1002 | 0x34 | 0x56 |
| 0x1003 | 0x56 | 0x34 |
| 0x1004 | 0x78 | 0x12 |
.cxx_destruct
.cxx_destruct⽅法是在ARC模式下⽤于释放成员变量的。只有当前类拥有实例变量时这个⽅法才会 出现,property⽣成的实例变量也算,且⽗类的实例变量不会导致⼦类拥有这个⽅法。
属性关联
AssociationsHashMap的初始化
获取内存大小的三种方式
- sizeof:计算某一类型占多大内存。参数可以是数组、指针、类型、对象、结构体、函数等。
- class_getInstanceSize:【<objc/runtime.h>】获取类的实例对象所占用的内存大小,并返回具体的字节数,其本质就是获取实例对象中成员变量的内存大小
- malloc_size:【<malloc/malloc.h>】对象实际分配的内存大小
成员变量存放在类对象的class_ro_t结构体当中。
类⽅法存在元类当中。
苹果为什么设计元类?
主要的⽬的是为了复⽤消息机制。在OC中调⽤⽅法,其实是在给某个对象发送某条消息。 消息的发送在编译的时候编译器就会把⽅法转换为objc_msgSend这个函数。 id objc_msgSend(id self, SEL op, …) 这个函数有俩个隐式的参数:消息的接收者,消息的⽅法 名。通过这俩个参数就能去找到对应⽅法的实现。 objc_msgSend函数就会通过第⼀个参数消息的接收者的isa指针,找到对应的类,如果我们是通过 实例对象调⽤⽅法,那么这个isa指针就会找到实例对象的类对象,如果是类对象,就会找到类对 象的元类对象,然后再通过SEL⽅法名找到对应的imp,然后就能找到⽅法对应的实现。 那如果没有元类的话,那这个objc_msgSend⽅法还得多加俩个参数,⼀个参数⽤来判断这个⽅法 到底是类⽅法还是实例⽅法。⼀个参数⽤来判断消息的接受者到底是类对象还是实例对象。 消息的发送,越快越好。那如果没有元类,在objc_msgSend内部就会有有很多的判断,就会影响 消息的发送效率。 所以元类的出现就解决了这个问题,让各类各司其职,实例对象就⼲存储属性值的事,类对象存储 实例⽅法列表,元类对象存储类⽅法列表,符合设计原则中的单⼀职责,⽽且忽略了对对象类型的 判断和⽅法类型的判断可以⼤⼤的提升消息发送的效率,并且在不同种类的⽅法⾛的都是同⼀套流 程,在之后的维护上也⼤⼤节约了成本。 所以这个元类的出现,最⼤的好处就是能够复⽤消息传递这套机制。不管你是什么类型的⽅法,都 是同⼀套流程。
在objc底层没有类⽅法和实例⽅法的区别,都是函数。
ro,rw,rwe class_ro_t是在编译的时候⽣成的。当类在编译的时候,类的属性,实例⽅法,协议这些内容就存 在class_ro_t这个结构体⾥⾯了,这是⼀块纯净的内存空间,不允许被修改。 class_rw_t是在运⾏的时候⽣成的,类⼀经使⽤就会变成class_rw_t,它会先将class_ro_t的内 容”拿”过去,然后再将当前类的分类的这些属性、⽅法等拷⻉到class_rw_t⾥⾯。它是可读写的。 class_rw_ext_t可以减少内存的消耗。苹果在wwdc2020⾥⾯说过,只有⼤约10%左右的类需要动 态修改。所以只有10%左右的类⾥⾯需要⽣成class_rw_ext_t这个结构体。这样的话,可以节约很 ⼤⼀部分内存。 class_rw_ext_t⽣成的条件: 第⼀:⽤过runtime的Api进⾏动态修改的时候。 第⼆:有分类的时候,且分类和本类都为⾮懒加载类的时候。实现了+load⽅法即为⾮懒加载类。
objc_msgSend
在iOS中调⽤⽅法其实就是在给对象发送某条消息。消息的发送在编译的时候编译器就会把⽅法转 换为objc_msgSend这个函数。objc_msgSend有俩个隐式的参数,消息的接收者和消息的⽅法 名。objc_msgSend这个函数就能够通过这俩个隐式的参数去找到⽅法具体的实现。如果消息的接 收者是实例对象,isa就指向类对象,后再通过第⼆个参数⽅法名,去类对象⾥⾯找对应的⽅法实 现。如果消息的接收者是类对象,isa就指向元类,就会去元类⾥⾯找对应的⽅法实现。
objc_msgSendSuper
发送消息到⽗类(使⽤super关键字),消息会使⽤objc_msgSendSuper发送。 super调⽤⽅法和self调⽤⽅法的区别就在于去找⽅法的时候出发点不⼀样⽽已。self会从当前类开 始去找,⽽super会从当前类的⽗类开始去找。
消息的快速查找流程
- 1.判断receiver(消息的接受者)是否存在
- 2.receiver -> isa -> class
- 3.class内存平移 -> cache
- 4.cache -> buckets
- 5.遍历buckets -> bucket(sel,imp)对⽐sel
- 6.如果bucket(sel,imp)对⽐sel 相等 –> cacheHit –> 调⽤imp
- 7.如果cache⾥⾯没有找到对应的sel –> _objc_msgSend_uncached
消息的慢速查找流程
lookUpImpOrForward – 先找当前类的methodList – superClass的cache – superClass的 methodList – 直到superClass为nil。
⽅法的动态决议
1
2
+(BOOL)resolveInstanceMethod:(SEL)sel;
+(BOOL)resolveClassMethod:(SEL)sel;
消息快速转发
1
2
-(id)forwardingTargetForSelector:(SEL)aSelector;
+(id)forwardingTargetForSelector:(SEL)aSelector;
消息慢速转发
1
2
3
4
5
6
-(NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector;
-(void)forwardInvocation:(NSInvocation *)anInvocation;
+(NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector;
+(void)forwardInvocation:(NSInvocation *)anInvocation;
⾯向切⾯编程与埋点
⾯向切⾯编程(AOP)在不修改源代码的情况下,通过运⾏时给程序添加统⼀功能的技术。 埋点就是在应⽤中特定的流程收集⼀些信息,⽤来跟踪应⽤使⽤的状况,然后精准分析⽤户数据。 ⽐如⻚⾯停留时间、点击按钮、浏览内容等等。
程序启动
在启动App时,真正的加载过程是从exec()函数开始,系统会调⽤exec()函数创建进程,并且分配 内存。然后会执⾏以下的操作
- 1、把App对应的可执⾏⽂件加载到内存。
- 2、把dyld加载到内存。dyld也是⼀个可执⾏的程序
- 3、dyld进⾏动态链接。
dyld的具体⼯作内容
- dyld会找到可执⾏⽂件的依赖动态库。接着dyld会将所依赖的动态库加载到内存中。这是⼀个 递归的过程,依赖的动态库可能还会依赖别的动态库,所以dyld会递归每个动态库,直⾄所有 的依赖库都被加载完毕。
- Rebase和Bind。rebase修复的是指向当前镜像内部的资源指针;⽽bind指向的是镜像外部的 资源指针
- 调起main函数,也就是我们程序的⼊⼝,然后我们的程序就开始执⾏了。
dyld进⾏初始化的流程
dyld是⽤来加载可执⾏⽂件所依赖的动态库的。然后会对可执⾏⽂件和可执⾏⽂件所依赖的动态库 进⾏初始化的操作。 在进⾏初始化的操作的时候⾸先会初始化libsystem,否则就会报错。因为在进⾏libsystem初始化 的时候,会初始化libdispatch,在进⾏libdispatch初始化的时候,会初始化libobjc,其他的库,可 能需要依赖runtime基础或者线程相关的基础。所以libsystem的初始化必须放在第⼀位。 在libobjc进⾏初始化的时候,会调⽤⼀个_dyld_objc_notify_register函数,这个函数会给dyld传递 三个回调函数。
- 1、map_images: dyld将image镜像⽂件加载进内存时,会触发该函数
- 2、load_images: dyld初始化image会触发该函数
- 3、unmap_image: dyld将image移除时会触发该函数 然后,dyld会调⽤ map_images 和 load_images 来对image进⾏初始化的操作。
_objc_init⾥⾯的初始化操作。
- 1、environ_init():环境变量的初始化
- 2、tls_init:创建线程的析构函数
- 3、static_init:运⾏C++静态构造函数
- 4、runtime_init:分类表初始化,类表初始化
- 5、cache_t::init():缓存的初始化
- 6、_imp_implementationWithBlock_init:关于macOS的相关操作。
- 7、didCallDyldNotifyRegister:标识对_dyld_objc_notify_register的调⽤已完成。
load_images
作⽤:执⾏类和分类的 load ⽅法。 load⽅法总结
- 1、当⽗类和⼦类都实现load函数时,⽗类的load⽅法执⾏顺序要优先于⼦类
- 2、当⼀个类未实现load⽅法时,不会调⽤⽗类load⽅法
- 3、类中的load⽅法执⾏顺序要优先于分类(Category)
- 4、load⽅法使⽤了锁,所以是线程安全的。
- 5、当有多个类别(Category)都实现了load⽅法,这⼏个load⽅法都会执⾏,但执⾏顺序不确定(其执⾏ 顺序与类别在Compile Sources中出现的顺序⼀致)
- 6、当然当有多个不同的类的时候,每个类load 执⾏顺序与其在Compile Sources出现的顺序⼀致
map_images
作⽤:进⾏类的初始化。
关键函数 read_images 流程
- 1、加载所有类到类的gdb_objc_realized_classes表中。
- 2、对所有类做重映射。
- 3、将所有SEL都注册到namedSelectors表中。
- 4、修复函数指针遗留。
- 5、将所有Protocol都添加到protocol_map表中。
- 6、对所有Protocol做重映射。
- 7、初始化所有⾮懒加载的类,进⾏rw、ro等操作。
- 8、遍历已标记的懒加载的类,并做初始化操作。
- 9、处理所有Category,包括Class和Meta Class。
- 10、初始化所有未初始化的类。
⾮懒加载类的初始化
关键函数: realizeClassWithoutSwift 关键代码:
1
2
3
4
5
6
7
8
9
10
11
12
//给rw开辟内存空间,然后将ro的数据“拷⻉”到rw⾥⾯。
rw = objc::zalloc<class_rw_t>();
rw->set_ro(ro);
rw->flags = RW_REALIZED|RW_REALIZING|isMeta;
cls->setData(rw);
//递归调⽤realizeClassWithoutSwift,对⽗类和元类进⾏初始化
supercls = realizeClassWithoutSwift(remapClass(cls->getSuperclass()), nil);
metacls = realizeClassWithoutSwift(remapClass(cls->ISA()), nil);
//设置⽗类,isa指针的初始化
cls->setSuperclass(supercls);
cls->initClassIsa(metacls);
分类的数据结构
1
2
3
4
5
6
7
8
struct _category_t {
const char *name;
struct _class_t *cls;
const struct _method_list_t *instance_methods;
const struct _method_list_t *class_methods;
const struct _protocol_list_t *protocols;
const struct _prop_list_t *properties;
};
为什么不能给分类添加成员变量?
因为分类的数据结构⾥⾯没有成员列表。
分类和类扩展的区别
分类原则上只能增加⽅法(可以通过rutime关联对象实现添加属性)。 类扩展不仅可以增加⽅法,还可以增加实例变量(或者属性)。 类扩展是在编译阶段被添加到类中,⽽分类是在运⾏时添加到类中。 类扩展不能像分类那样拥有独⽴的实现部分(@implementation部分),也就是说,类扩展所 声明的⽅法必须依托对应类的实现部分来实现。 定义在 .m ⽂件中的类扩展⽅法为私有的,定义在 .h ⽂件(头⽂件)中的类扩展⽅法为公有 的。类扩展是在 .m ⽂件中声明私有⽅法的⾮常好的⽅式。
分类的加载
- 类为⾮懒加载类/分类为⾮懒加载类 编译时ro⾥⾯只有类的数据没有分类的数据,分类的数据在运⾏是被加载到rwe⾥⾯。
- 类为⾮懒加载类/分类为懒加载类 编译时类和分类的数据都被加载ro⾥⾯了。
- 类为懒加载类/分类为⾮懒加载类 编译时类和分类的数据都被加载ro⾥⾯了。
- 类为懒加载类/分类懒加载类 在类第⼀次接收到消息时加载数据,类和分类的数据都被加载在ro⾥⾯。
线程与进程
- 进程是指在系统中正在运⾏的⼀个应⽤程序,每个进程之间是独⽴的,每个进程均运⾏在其专 ⽤的且受保护的内存空间内
- 线程是进程的基本执⾏单元,⼀个进程的所有任务都在线程中执⾏,进程要想执⾏任务,必须 得有线程,进程⾄少要有⼀条线程。程序启动会默认开启⼀条线程,这条线程被称为主线程或 UI 线程
线程调度与时间⽚
⼀个 CPU 核⼼同⼀时刻只能执⾏⼀个线程。当线程数量超过 CPU 核⼼数量时,⼀个 CPU 核⼼往 往就要处理多个线程,这个⾏为叫做线程调度。 就是 ⼀个CPU 核⼼轮流让各个线程分别执⾏⼀段 时间,也就是说⼀个设备并发执⾏的线程数量是有限的。CPU在多个任务直接进⾏快速的切换,这 个时间间隔就是时间⽚。
线程的生命周期
GCD的中的队列
队列的作⽤是⽤来存储任务。队列分类串⾏队列和并发队列。串⾏队列和并发队列都是 FIFO ,也 就是先进先出的数据结构。
- 串⾏队列 :它的DQF_WIDTH等于1,相当以它只有⼀条通道。所以队列中的任务要串⾏执⾏,也就 是⼀个⼀个的执⾏,必须等上⼀个任务执⾏完成之后才能开始下⼀个,⽽且⼀定是按照先进先出的 顺序执⾏的,⽐如串⾏队列⾥⾯有4个任务,进⼊队列的顺序是a、b、c、d,那么⼀定是先执⾏ a,并且等任务a完成之后,再执⾏b… 。
- 并发队列 :它的DQF_WIDTH⼤于1,相当于有多条通道。队列中的任务可以并发执⾏,也就任务可 以同时执⾏,⽐如并发队列⾥⾯有4个任务,进⼊队列的顺序是a、b、c、d,那么⼀定是先执⾏ a,再执⾏b…,也是按照先进先出(FIFO, First-In-First-Out)的原则调⽤的,但是执⾏b的时候a 不⼀定执⾏完成,⽽且a和b具体哪个先执⾏完成是不确定的。通道有很多,哪个任务先执⾏完得看 任务的复杂度,以及cpu的调度情况。
GCD产⽣死锁的原因
在当前线程(线程所执⾏的任务是从当前队列取出来的)同步的向串⾏队列⾥⾯添加任务,就会产 ⽣死锁。
同步函数的特点
- 阻塞当前线程进⾏等待,直到当前添加到队列的任务执⾏完成。
- 只能在当前线程执⾏任务,不具备开启新线程的能⼒。
异步函数的特点
- 不会阻塞线程,不需要等待,任务可以继续执⾏。
- 可以在新的线程执⾏任务,具备开启新线程的能⼒。(并发队列可以开启多条⼦线程,串⾏队 列只能开启⼀条⼦线程)
互斥锁
保证在任何时候,都只有一个线程访问对象。当获取锁操作失败时,线程会进入睡眠,等待锁释放时被唤醒;(闲等)
自旋锁
与互斥锁有点类似,只是自旋锁 不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环尝试(忙等),直到该自旋锁的保持者已经释放了锁;因为不会引起调用者睡眠,所以效率高于互斥锁;
互斥锁和自旋锁的加锁原理
- 互斥锁:线程会从sleep(加锁)-> running(解锁),过程中有上下文的切换,cpu的抢占,信号的发送等开销。
- 自旋锁:线程一直是running(加锁 -> 解锁),死循环检测锁的标志位,机制不复杂。
Comments powered by Disqus.